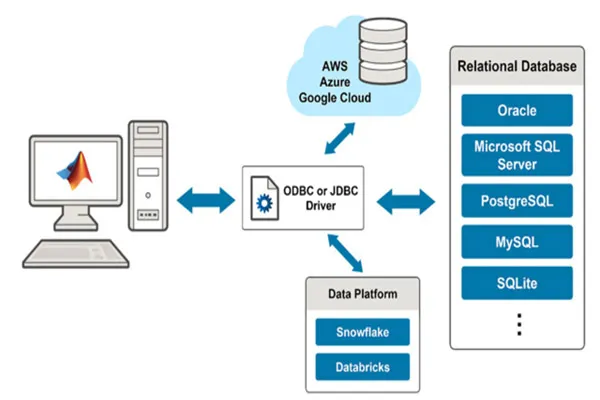
1. Define the Problem
- Identify the goal: What problem do you want the AI/ML system to solve? This could be anything from image classification, natural language processing (NLP), predictive modeling, recommendation systems, etc.
- Set clear objectives: Determine what success looks like and how you will evaluate the system's performance.
2. Collect and Prepare Data
- Data collection: Gather the data necessary for training the model. The quality and quantity of data will directly impact the performance of your AI system. Data could come from sensors, databases, websites, or even open datasets available online.
- Data cleaning: This step involves removing noise, correcting errors, and dealing with missing values in the dataset.
- Feature selection and engineering: Identify the most relevant features (or attributes) in the data and possibly create new ones to improve the model’s performance.
- Data splitting: Typically, the dataset is divided into training, validation, and test sets.
3. Choose an Algorithm
- Supervised Learning: Involves training a model on labeled data (data with known outputs). Algorithms include Linear Regression, Decision Trees, SVM, Neural Networks, etc.
- Unsupervised Learning: Deals with unlabeled data and aims to identify patterns or structures, like clustering and dimensionality reduction. Examples include K-means clustering and PCA (Principal Component Analysis).
- Reinforcement Learning: The system learns by interacting with an environment and receiving feedback in the form of rewards or penalties. It’s used in robotics, games, etc.
- Deep Learning: A subset of ML using neural networks with multiple layers. It's effective for complex tasks like image recognition, NLP, and time-series analysis.
Choose an algorithm based on the type of problem you're solving, data availability, and desired complexity.
4. Model Training
- Select the model architecture: If you're using deep learning, you might choose from architectures like Convolutional Neural Networks (CNNs) for images or Recurrent Neural Networks (RNNs) for time series data.
- Training the model: Use the training data to teach the model to recognize patterns. This involves feeding data through the algorithm and adjusting the model's parameters (weights and biases) to minimize the error or loss function.
- Hyperparameter tuning: During training, you’ll likely need to tune various hyperparameters (e.g., learning rate, batch size, number of layers) to improve performance.
5. Evaluate the Model
- Validation: After training, evaluate the model’s performance on a validation dataset. This allows you to check if the model is overfitting or underfitting.
- Metrics: Choose appropriate metrics to measure the model’s accuracy. Examples include precision, recall, F1-score, confusion matrix, ROC-AUC for classification, and Mean Squared Error (MSE) for regression.
- Cross-validation: You can use k-fold cross-validation to further validate the model’s robustness by training and testing on different subsets of the data.
6. Model Optimization
- Fine-tuning: Based on the performance evaluation, you may need to fine-tune your model. This can involve adjusting the model architecture, data preprocessing steps, or using advanced techniques like ensemble methods.
- Regularization: Techniques like L1/L2 regularization, dropout (in deep learning), and early stopping can help prevent overfitting.
7. Test the Model
- Testing: Once you're satisfied with the model's performance on the validation set, test it on the unseen test set to assess its generalization capabilities.
- Error analysis: Analyze the errors the model makes to see if there are any patterns or ways to improve the model further.
8. Deploy the Model
- Model deployment: Once the model performs well, deploy it to a production environment where it can start interacting with real users or systems.
- APIs and microservices: In many cases, you might expose the trained model via an API, allowing other systems to interact with it (e.g., sending data and receiving predictions).
- Scalability: Make sure the system can handle scaling up if needed, whether through cloud-based solutions or optimized hardware.
9. Monitor and Maintain the Model
- Monitor performance: Once the model is in production, continuously monitor its performance and make adjustments as needed.
- Retraining: The model might need retraining over time with new data to adapt to changes in patterns or to improve performance.
- A/B testing: Conduct experiments to compare different versions of the model or alternative algorithms.
10. Ethical and Responsible AI
- Bias and fairness: Ensure your model does not discriminate against specific groups of people, which can happen if the training data is biased.
- Transparency and explainability: For some applications, you may need to make sure the AI decisions are explainable, especially in critical areas like healthcare or finance.
- Privacy: Make sure the system respects user privacy, especially when dealing with sensitive data.