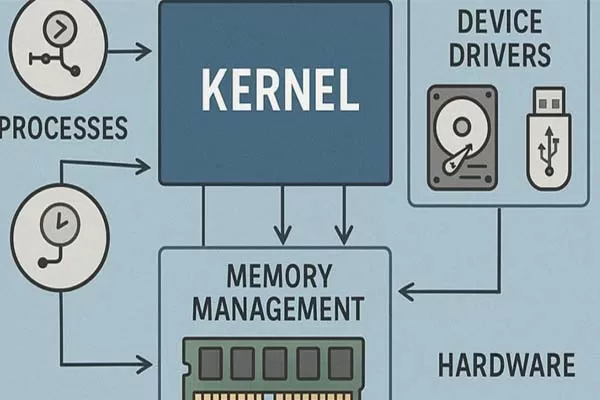
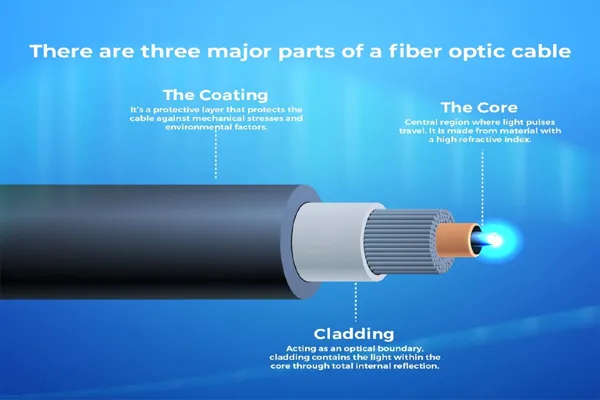
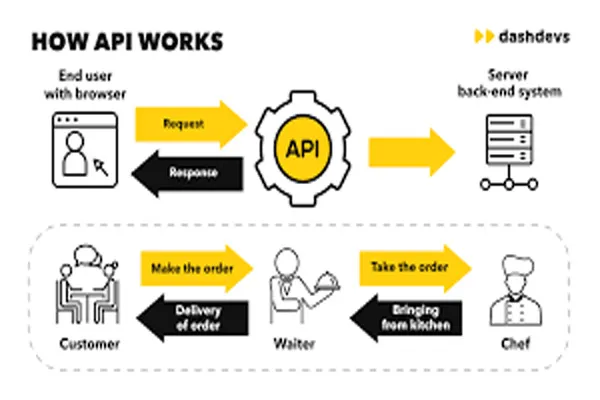
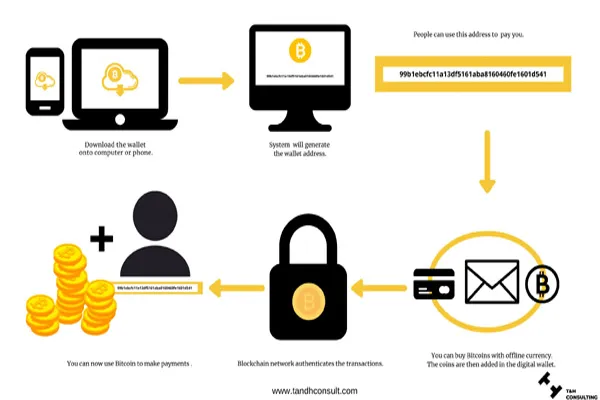
Wikipedia plays a significant role in the development of large language models (LLMs) used in AI search systems. As one of the largest and most comprehensive freely available repositories of human knowledge, Wikipedia provides a vast, structured dataset that AI developers often use to train LLMs. These models, which power tools like chatbots and search engines, rely on massive amounts of text to learn patterns, facts, and relationships in language. Wikipedia’s openly accessible articles—covering millions of topics in multiple languages—make it an ideal resource for this purpose.
Many LLMs, such as those developed by OpenAI (e.g., ChatGPT), Google, or others, are trained on diverse corpora that include publicly available internet texts. While specific training datasets are often proprietary and not fully disclosed, Wikipedia is widely acknowledged as a common component due to its size, quality, and accessibility. For instance, the English Wikipedia alone contains over 6 million articles, offering a broad foundation of general knowledge that helps LLMs understand context, answer questions, and generate human-like responses.
In the context of AI search, Wikipedia’s contribution goes beyond just training data. Some AI systems use retrieval-augmented generation (RAG), where the model fetches real-time or pre-indexed information from sources like Wikipedia to provide up-to-date or factual answers. This enhances the accuracy of search results, as the AI can ground its responses in verified content rather than relying solely on its pre-trained knowledge, which might be outdated or incomplete.
However, Wikipedia’s role isn’t without challenges. Its content, while generally reliable, is user-generated and can contain biases, errors, or gaps, which LLMs might inherit. Additionally, debates within the Wikipedia community about AI-generated content being used on the platform itself highlight a feedback loop: LLMs trained on Wikipedia could, in turn, influence its future content, potentially amplifying inaccuracies or skewing perspectives.
In summary, yes, Wikipedia significantly contributes to LLMs for AI search by providing a foundational dataset for training and a reference for real-time information retrieval. Its impact is profound, shaping how AI systems understand and respond to queries, though it comes with the caveat that the quality and limitations of Wikipedia’s content can directly affect the performance of these models.